Inventory Management Transfer
Continuing in our series of posts about creating a basic Scalatra service for managing inventory, we would now like to implement the persistence logic to transfer inventory from one location to another.
Previous posts for our inventory service:
WARNING - This may be difficult to follow if you haven't been working through the previous posts. Reviewing this repository that implements this material covered so far may help you https://bitbucket.org/honstain/scalatra-single-record-transfer-service/src/master/
Transfer Inventory Between Locations
NOTE - I am going to intentionally start with naive implementation and demonstrate testing it (exposing issues). We will iterate on the design together.
Let's establish some basic requirements or expectations for this logic. We may initially relax some of these requirements to illustrative purposes (but this is where we are going).
- The source location must exist when attempting to transfer a SKU+qty from a source location to a destination location.
- The source location has enough inventory to supply the requested qty being transferred. Said another way, we will not support going negative.
To illustrate, if we wanted to transfer 1 unit of 'SKU-01' from location 'LOC-01' to 'LOC-02'.
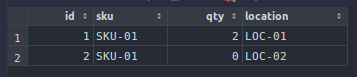
We will want to remove one from 'LOC-01' and then increase the quantity of 'LOC-02'. An initial test to help us validate this behavior for our DAO might look like:
def createInventoryHelper(sku: String, qty: Int, location: String): InventorySingleRecord = {
val create = InventorySingleRecordDao.create(database, sku, qty, location)
Await.result(create, Duration.Inf).get
}
test("transfer") {
createInventoryHelper(TEST_SKU, 1, BIN_01)
createInventoryHelper(TEST_SKU, 0, BIN_02)
val futureTrans = InventorySingleRecordDao.transfer(database, TEST_SKU, 1, BIN_01, BIN_02)
Await.result(futureTrans, Duration.Inf)
val futureFind = InventorySingleRecordDao.findAll(database)
val findResult: Seq[InventorySingleRecord] = Await.result(futureFind, Duration.Inf)
findResult should contain only (
InventorySingleRecord(Some(1), "NewSku", 0, BIN_01),
InventorySingleRecord(Some(2), "NewSku", 1, BIN_02),
)
}
Now to implement the InventorySingleRecordDao.transfer logic we can reference the upsert logic from our previous post that uses the Scala for comprehension and a database transaction. We can start by just modifying the source location and ignore the destination location (the test won't pass, but we will be able to validate our transfer logic incrementally).
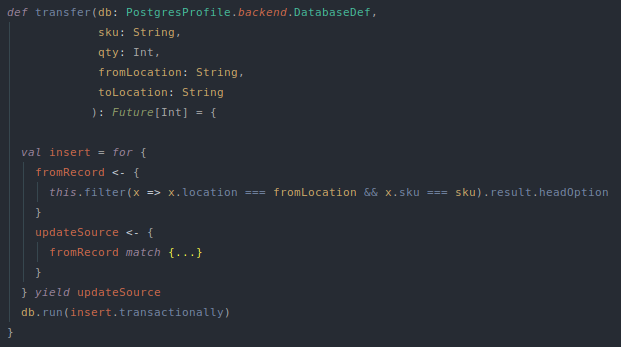
This gives us a basic overview of the transfer function in our DAO. We have a for comprehension with the query to retrieve the database record for the source (fromLocation) and then attempt to modify it (there is basic handling to address the possibility that we don't find the source record.
def transfer(db: PostgresProfile.backend.DatabaseDef,
sku: String,
qty: Int,
fromLocation: String,
toLocation: String
): Future[Int] = {
val insert = for {
fromRecord <- {
this.filter(x => x.location === fromLocation && x.sku === sku).result.headOption
}
updateSource <- {
fromRecord match {
case Some(InventorySingleRecord(_, `sku`, srcQty, `fromLocation`)) =>
val q = for { x <- this if x.location === fromLocation && x.sku === sku } yield x.qty
q.update(srcQty - qty)
case _ =>
DBIO.failed(new Exception("Failed to find source location"))
}
}
} yield updateSource
db.run(insert.transactionally)
}
Running the test that just created, we will get a failure, but hopefully, be able to see that the source 'Bin-01' is decremented.
Vector(
InventorySingleRecord(Some(2),NewSku,0,Bin-02),
InventorySingleRecord(Some(1),NewSku,0,Bin-01))
did not contain only (
InventorySingleRecord(Some(1),NewSku,0,Bin-01),
InventorySingleRecord(Some(2),NewSku,1,Bin-02))Now we need to update the destination record.
Just like when we updated the source location, we will want to query for it, but it is more likely that this record does not already exist (at least in this example where we assume physical inventory already exists in a source location, but its much more likely that the sku+location combination of the destination is unknown to the database - remember that those two columns are integral to our design).
toRecord <- {
this.filter(x => x.location === toLocation && x.sku === sku).result.headOption
}
Now that we possibly have a record for the destination, we can try to update or create. This should be very familiar if you worked through the upsert logic in my previous post.
createUpdateDestination <- {
toRecord match {
case Some(InventorySingleRecord(_, `sku`, destQty, `toLocation`)) =>
// Update
logger.debug(s"Transfer from:$fromLocation to $toLocation found $destQty in destination")
val q = for { x <- this if x.location === toLocation && x.sku === sku } yield x.qty
q.update(destQty + qty)
case _ =>
// Create - this is likely susceptible to write skew
this += InventorySingleRecord(Option.empty, sku, qty, toLocation)
}
}
Hopefully, with these pieces all put together you get a passing test.
Current Code for a Very Basic Transfer of Inventory
def transfer(db: PostgresProfile.backend.DatabaseDef,
sku: String,
qty: Int,
fromLocation: String,
toLocation: String
): Future[Int] = {
val insert = for {
toRecord <- {
this.filter(x => x.location === toLocation && x.sku === sku).result.headOption
}
fromRecord <- {
this.filter(x => x.location === fromLocation && x.sku === sku).result.headOption
}
createUpdateDestination <- {
toRecord match {
case Some(InventorySingleRecord(_, `sku`, destQty, `toLocation`)) =>
// Update
logger.debug(s"Transfer from:$fromLocation to $toLocation found $destQty in destination")
val q = for { x <- this if x.location === toLocation && x.sku === sku } yield x.qty
q.update(destQty + qty)
case _ =>
this += InventorySingleRecord(Option.empty, sku, qty, toLocation)
}
}
updateSource <- {
fromRecord match {
case Some(InventorySingleRecord(_, `sku`, srcQty, `fromLocation`)) =>
val q = for { x <- this if x.location === fromLocation && x.sku === sku } yield x.qty
q.update(srcQty - qty)
case _ =>
DBIO.failed(new Exception("Failed to find source location"))
}
}
} yield updateSource
db.run(insert.transactionally)
}
Exposing the Flaws in this Initial Design
At this stage we hopefully have a basic DAO that implements the following.
def findAll(db: PostgresProfile.backend.DatabaseDef): Future[Seq[InventorySingleRecord]]
def create(db: PostgresProfile.backend.DatabaseDef,
sku: String,
qty: Int,
location: String
): Future[Option[InventorySingleRecord]]
def transfer(db: PostgresProfile.backend.DatabaseDef,
sku: String,
qty: Int,
fromLocation: String,
toLocation: String
): Future[Int]
I created a repository with a working Scala Scalatra service to snapshot this stage of the development:
This repo provides you an example of Scalatra service that exposes our DAO operations via a set of crude HTTP endpoints. The README.md provides some points on starting the service. If this is unfamiliar or you would like a refresher, I suggest reviewing the previous post where I covered just this aspect of Scalatra http://honstain.com/rest-in-a-scalatra-service/.
Before beginning this next step, I suggest you verify that you have a service that runs, with a database, and can respond to HTTP requests.
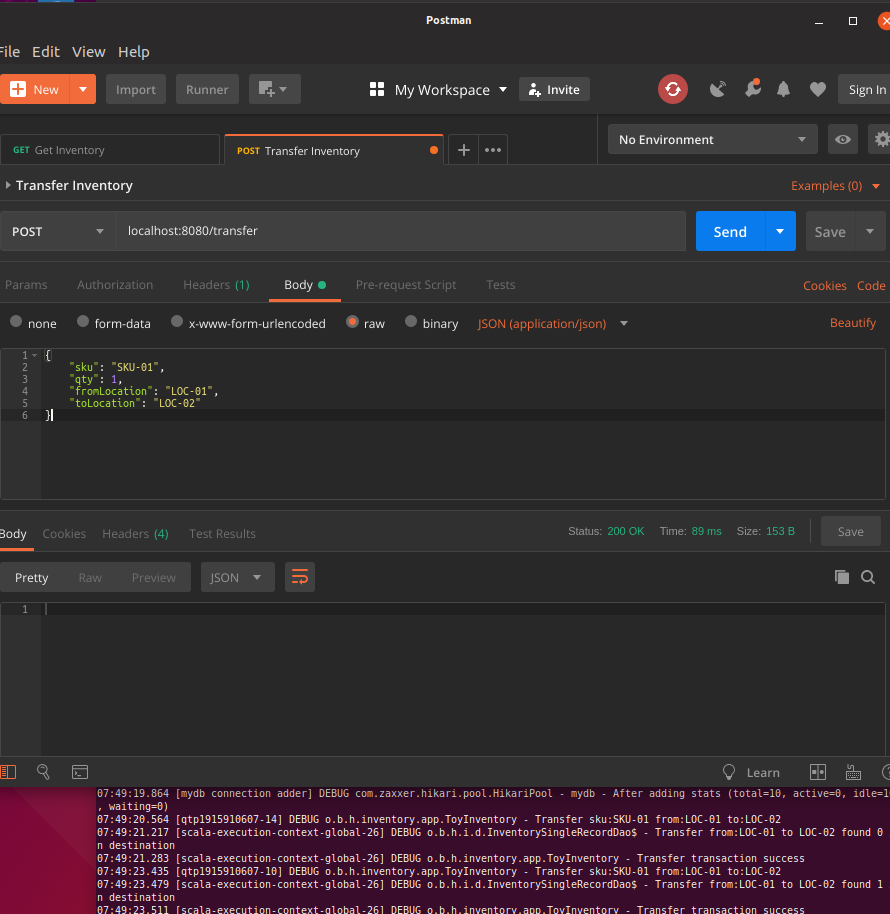
Using a tool like Postman to transfer inventory between LOC-01 and LOC-02 you may notice that doesn't enforce any constraints yet, it can result in negative quantities and moving negative amounts. What we are really interested in how consistent the database will be with our current DAO queries.
Exposing Consistency Problems
One way to test our system might be to attempt to move inventory in parallel (for the same SKU and location group). Let's start with just two locations and a single SKU, trying to move back and forth between LOC-01 and LOC-02 should be enough to expose an issue.
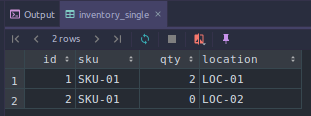
There are several tools that you could use for load and performance testing. You could even write your own script or test. I have opted to use siege which is a common command line tool you can probably retrieve from your Linux package manager (https://www.joedog.org/siege-home/). By defining a set of URLs we will use siege to execute the following in parallel:
- Get all the inventory
- Transfer 1 qty of SKU
SKU-01fromLOC-01toLOC-02 - Transfer 1 qty of SKU
SKU-01fromLOC-02toLOC-01
# siege_urls.txt - a urls file https://www.joedog.org/siege-manual/#a05
127.0.0.1:8080/
127.0.0.1:8080/transfer POST {"sku": "SKU-01","qty": 1,"fromLocation": "LOC-01","toLocation": "LOC-02"}
127.0.0.1:8080/transfer POST {"sku": "SKU-01","qty": 1,"fromLocation": "LOC-02","toLocation": "LOC-01"}
This command will start siege running with the following arguments:
-vverbose mode-c22 concurrent requests-r10run the test 10 times--content-typespecifying the content type for our API-fthe URLs file
siege -v -c2 -r10 --content-type "application/json" -f siege_urls.txt
** SIEGE 4.0.4
** Preparing 2 concurrent users for battle.
The server is now under siege...
HTTP/1.1 200 0.01 secs: 91 bytes ==> GET /
HTTP/1.1 200 0.07 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.06 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.04 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.00 secs: 91 bytes ==> GET /
HTTP/1.1 200 0.03 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.02 secs: 91 bytes ==> GET /
HTTP/1.1 200 0.04 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.04 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.04 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.01 secs: 91 bytes ==> GET /
HTTP/1.1 200 0.07 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.01 secs: 92 bytes ==> GET /
HTTP/1.1 200 0.06 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.05 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.07 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.01 secs: 91 bytes ==> GET /
HTTP/1.1 200 0.05 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
HTTP/1.1 200 0.01 secs: 92 bytes ==> GET /
HTTP/1.1 200 0.04 secs: 0 bytes ==> POST http://127.0.0.1:8080/transfer
Transactions: 20 hits
Availability: 100.00 %
Elapsed time: 0.38 secs
Data transferred: 0.00 MB
Response time: 0.04 secs
Transaction rate: 52.63 trans/sec
Throughput: 0.00 MB/sec
Concurrency: 1.92
Successful transactions: 20
Failed transactions: 0
Longest transaction: 0.07
Shortest transaction: 0.00
Keeping in mind that we started with qty 2 in LOC-01 and qty 0 in LOC-02, let's see what we have now? NOTE - you will likely have different results, if the results look good please repeat the test since we are trying to demonstrate a concurrency issue.
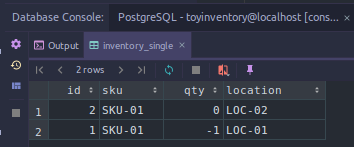
You can look through the logs of the Scalatra service and try to spot where things first go off the rails. I added the following log line to the update source section.
updateSource <- {
fromRecord match {
case Some(InventorySingleRecord(_, `sku`, srcQty, `fromLocation`)) =>
val destinationQty: Int = if (toRecord.isDefined) toRecord.get.qty else 0
logger.debug(s"Transfer $qty from:$fromLocation (had qty:$srcQty) to $toLocation (had qty:$destinationQty)")
val q = for { x <- this if x.location === fromLocation && x.sku === sku } yield x.qty
q.update(srcQty - qty)
case _ =>
DBIO.failed(new Exception("Failed to find source location"))
}
}
An example of my Scalatra logs that demonstrate our consistency issue:
# Two siege calls happen in close succession, both see qty 2 and move 1
Transfer 1 from:LOC-01 (had qty:2) to LOC-02 (had qty:0)
Transfer 1 from:LOC-01 (had qty:2) to LOC-02 (had qty:0)
# Two siege calls happen again but find that only 1 unit was moved
# We are already in an inconsistent state
Transfer 1 from:LOC-02 (had qty:1) to LOC-01 (had qty:1)
Transfer 1 from:LOC-02 (had qty:1) to LOC-01 (had qty:1)
# The problem just spirals out from here.
Transfer 1 from:LOC-01 (had qty:2) to LOC-02 (had qty:0)
Transfer 1 from:LOC-01 (had qty:1) to LOC-02 (had qty:0)
Transfer 1 from:LOC-02 (had qty:1) to LOC-01 (had qty:1)
Transfer 1 from:LOC-02 (had qty:0) to LOC-01 (had qty:2)
Why is this happening? First let's consider that we are executing multiple queries in a transaction, but our isolation level is the default Read Committed https://www.postgresql.org/docs/9.1/transaction-iso.html. Both transactions overlap and as a result one of the clients does not cause the desired change.
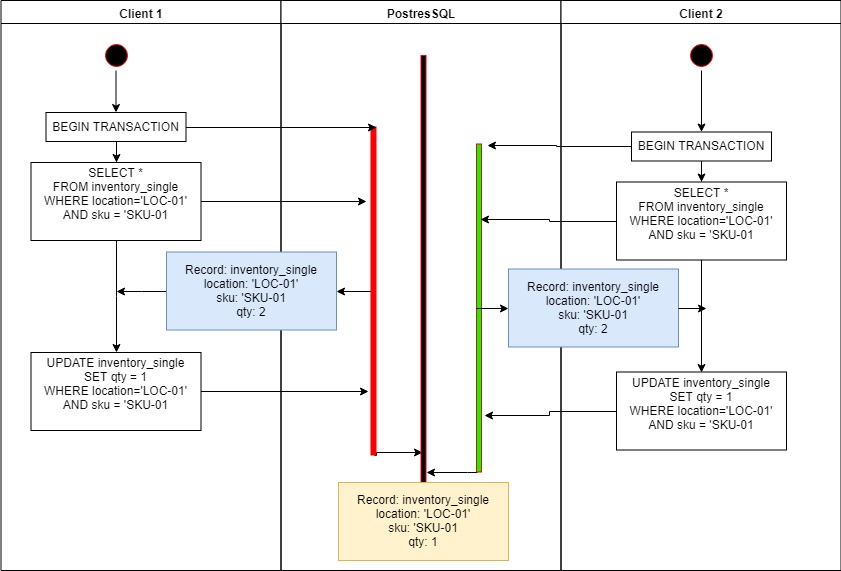
Attempt to Enforce Consistency
Often the first thing people reach for is to ratchet up the isolation level and let the database sort things out. We will try that approach and jump our query up to Serializable isolation level and see what happens.
db.run(insert.transactionally.withTransactionIsolation(TransactionIsolation.Serializable))
Running siege again you might see something like this:
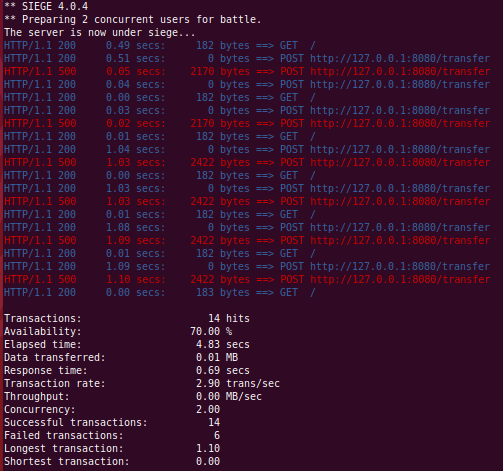
NOTE ON SIEGE - Siege is a brute force sort of tool, it will blindly attempt to keep cycling through its URLs. Hence a previous failure will not cause it to stop or retry (as currently configured), leading to unusual behavior for larger numbers of iterations as it makes no attempt to model a real user or the physical world.
I have organized the log data to better illustrate the success and failure of each call (assigning a color to each distinct transfer call). Note that I also started passing around a user id (random int assigned at the start of the rest call) to help us trace things, it probably would have been better if I referenced it as a tracing id / provenance id).

Now we have consistent data, but PostgreSQL is achieving that by aborting our transactions whenever it identifies a problem. It is helpful to reference the PostgreSQL docs at this stage https://www.postgresql.org/docs/9.1/transaction-iso.html

If you siege long enough, you may also observe PostgreSQL identify and kill a deadlock.
14:40:20.312 [scala-execution-context-global-39] DEBUG o.b.h.inventory.app.ToyInventory - user: 543 - ERROR: deadlock detected
Detail: Process 25421 waits for ShareLock on transaction 206692; blocked by process 25419.
Process 25419 waits for ShareLock on transaction 206691; blocked by process 25421.
Hint: See server log for query details.
Where: while updating tuple (0,91) in relation "inventory_single"I will leave it to the reader to try Repeatable Read as an exercise.
Summary
We have made an attempt to implement the functionality for modeling the transfer of physical inventory from one location to another. While tests pass and things work on the happy path, when we introduce concurrency we have problems. In our next post we will explore some additional options to help us maintain consistency.