Inventory Transfer Consistently
In our previous post, we designed a basic system to track the physical transfer of goods between two physical locations.
Previous posts for our inventory service:
- Part 1 - Creating a Scalatra Inventory Management Service
- Part 2 - Implementing Create/Update in Slick
- Part 3 - Inventory Management Transfer
WARNING - This may be difficult to follow if you haven't been working through the previous posts. Reviewing this repository that implements this material covered so far may help you https://bitbucket.org/honstain/scalatra-single-record-transfer-service/src/master/
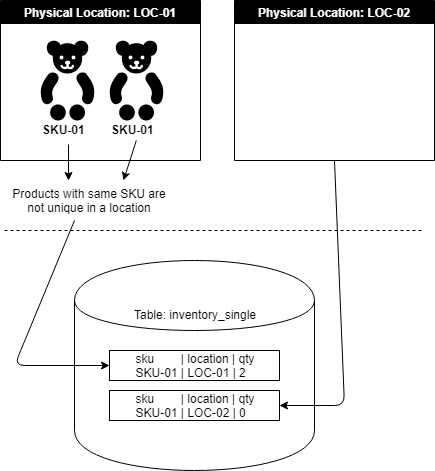
I created a basic diagram to help better visualize the sort of relationship and model we are dealing with in this walk-through.
Enforcing Consistency in the Database
When we left off in our previous post we had a solution that worked for the simple happy path, but would quickly manifest undesirable behavior under mild concurrency.
Our initial attempts focused on using a more restricted database isolation level. But as we saw from our testing, it exposed a lot of errors to the client (while using Serializable the database would detect and abort our transactions). We could attempt to retry, but we would need to think through any approach with retry holistically to make sure retry was still valid given the new state of the database.
Possible options consider going forward:
- Retry our database serialization failures (if using the Serializable isolation level).
- Remember that there are non-trivial performance implications to serializing, but like with anything it would be to your benefit to experiment and make an informed decision for your use case and read patterns.
- Pessimistic row level locking - we use the database to block access specific rows while we execute our logic and do the update. https://www.postgresql.org/docs/9.0/sql-select.html#SQL-FOR-UPDATE-SHARE
- Optimistic offline lock - by assuming the risk of conflict is low (especially if multiple services are involved) we rely on a revision id and some additional logic in the client/callers identify potential issues.
- Martin Flower has a great reference https://martinfowler.com/eaaCatalog/optimisticOfflineLock.html
These are just a few directions you could go, you could even attempt to circumvent this problem entirely with some alternative technology solutions. Because this series of blog posts are centered around Scala, relational databases, and microservices, I will focus our exploration ways to work the problem using traditional database techniques.
Row Level Locking
Our next attempt will be to use row level locking to help us prevent multiple concurrent users from conflicting with one another.
A excellent reference to review before continuing would be to review the PostgreSQL documentation on select for update SQL. https://www.postgresql.org/docs/9.0/sql-select.html#SQL-FOR-UPDATE-SHARE
Slick provides us access to PostgreSQL row-level locking with the forUpdate method on the Query class.
- Before we add row level locking - this is our original transfer function:
def transfer(db: PostgresProfile.backend.DatabaseDef,
sku: String,
qty: Int,
fromLocation: String,
toLocation: String
): Future[Int] = {
val insert = for {
toRecord <- {
this.filter(x => x.location === toLocation && x.sku === sku).result.headOption
}
fromRecord <- {
this.filter(x => x.location === fromLocation && x.sku === sku).result.headOption
}
createUpdateDestination <- {
toRecord match {
case Some(InventorySingleRecord(_, `sku`, destQty, `toLocation`)) =>
// Update
val q = for { x <- this if x.location === toLocation && x.sku === sku } yield x.qty
q.update(destQty + qty)
case _ =>
// Create - this is likely susceptible to write skew
this += InventorySingleRecord(Option.empty, sku, qty, toLocation)
}
}
updateSource <- {
fromRecord match {
case Some(InventorySingleRecord(_, `sku`, srcQty, `fromLocation`)) =>
val destinationQty: Int = if (toRecord.isDefined) toRecord.get.qty else 0
logger.debug(s"Transfer $qty from:$fromLocation (had qty:$srcQty) to $toLocation (had qty:$destinationQty)")
val q = for { x <- this if x.location === fromLocation && x.sku === sku } yield x.qty
q.update(srcQty - qty)
case _ =>
DBIO.failed(new Exception("Failed to find source location"))
}
}
} yield updateSource
db.run(insert.transactionally)
}
- After we just need to add forUpdate to the initial select queries.
toRecord <- {
this.filter(x => x.location === toLocation && x.sku === sku).forUpdate.result.headOption
}
fromRecord <- {
this.filter(x => x.location === fromLocation && x.sku === sku).forUpdate.result.headOption
}
Let's test this change by trying to run more than one transfer in parallel. We will use the same approach from our previous post (creating the initial transfer functionality), where we used the Linux command line tool siege.
siege -v -c2 -r10 --content-type "application/json" -f siege_urls.txtPlease make sure your database data looks like the following:
The results of our concurrent requests looked like this (we had a few failures).
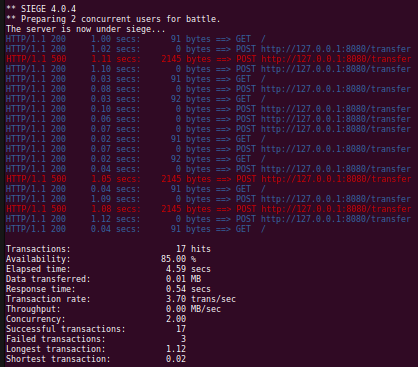
Looking to the logs from Scalatra, you can see PostgreSQL encountered a deadlock, looking at the response times also shows how painful the deadlock was to identify for the database.
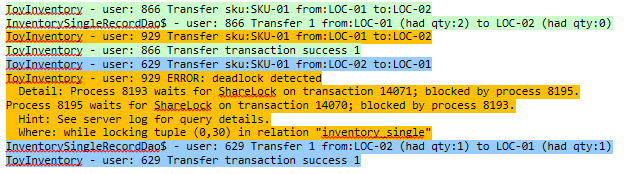
At some point the requests overlapped in such a way that our fictitious user 929 had taken a lock on LOC-01 and then wanted to lock LOC-02 only to find that user 629 already had a lock on LOC-02 and wanted LOC-01. It would be a good idea to review the PostgreSQL documentation on deadlocks https://www.postgresql.org/docs/9.5/explicit-locking.html. I found it helpful to turn on query logging in PostgreSQL https://stackoverflow.com/questions/722221/how-to-log-postgresql-queries if you want even more information about what is happening.
2019-04-18 07:22:23.790 PDT [8195] toyinventory@toyinventory ERROR: deadlock detected
2019-04-18 07:22:23.790 PDT [8195] toyinventory@toyinventory DETAIL: Process 8195 waits for ShareLock on transaction 14078; blocked by process 8193.
Process 8193 waits for ShareLock on transaction 14079; blocked by process 8195.
Process 8195: select "id", "sku", "qty", "location" from "inventory_single" where ("location" = 'LOC-02') and ("sku" = 'SKU-01') for update
Process 8193: select "id", "sku", "qty", "location" from "inventory_single" where ("location" = 'LOC-01') and ("sku" = 'SKU-01') for update How Do We Fix This?
As described in the documentation for PostgreSQL https://www.postgresql.org/docs/9.5/explicit-locking.html#LOCKING-DEADLOCKS
The best defense against deadlocks is generally to avoid them by being certain that all applications using a database acquire locks on multiple objects in a consistent order.
How would we go about acquiring our locks in a consistent order? In our code, the first lock we take is the destination location (note the ordering of our current operations in our transfer DAO method is fairly arbitrary).
def transfer(db: PostgresProfile.backend.DatabaseDef,
sku: String,
qty: Int,
fromLocation: String,
toLocation: String,
userId: String
): Future[Int] = {
val insert = for {
toRecord <- {
this.filter(x => x.location === toLocation && x.sku === sku).forUpdate.result.headOption
}
fromRecord <- {
this.filter(x => x.location === fromLocation && x.sku === sku).forUpdate.result.headOption
}
What if we added a new step at the very beginning that was only responsible for taking out database locks in a consistent order?
We can start by always taking our first lock on the smallest (by ordering of the location string) location and our second lock on the largest.
val locations = List(fromLocation, toLocation)
val firstLocationToLock = locations.min
val secondLocationToLock = locations.max
Then add two more queries to our Slick for-comprehension. In this case, we can ignore the response, I leave it as an exercise to the reader if they want to reorganize this Slick query into only 4 database queries (I have chosen to be wasteful in an effort to be simple to understand for the purpose of illustration).
val locations = Seq(fromLocation, toLocation)
val firstLocationToLock = locations.min
val secondLocationToLock = locations.max
val insert = for {
_ <- {
this.filter(x => x.location === firstLocationToLock && x.sku === sku).forUpdate.result.headOption
}
_ <- {
this.filter(x => x.location === secondLocationToLock && x.sku === sku).forUpdate.result.headOption
}
toRecord <- {
this.filter(x => x.location === toLocation && x.sku === sku).result.headOption
}
fromRecord <- {
this.filter(x => x.location === fromLocation && x.sku === sku).result.headOption
}
With our changes, lets make sure the automated tests still pass and then attempt to do concurrent transfers.
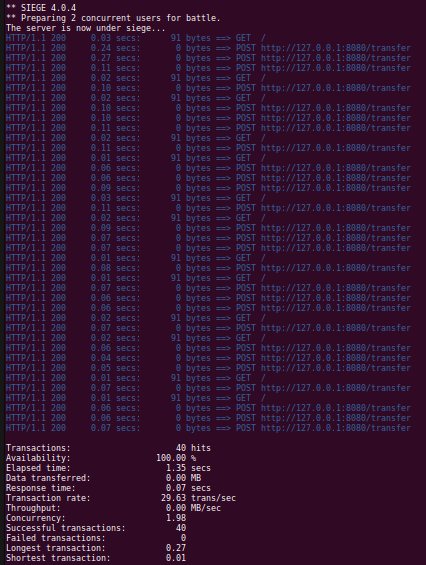
These results look much more promising than our previous attempts. You should review the Scalatra service logs to confirm the result. We can review the PostgreSQL query logs to see if the queries are matching our expectations.
2019-04-18 08:08:13.925 PDT [11853] toyinventory@toyinventory LOG: execute S_2: BEGIN
2019-04-18 08:08:13.925 PDT [11853] toyinventory@toyinventory LOG: execute S_3: select "id", "sku", "qty", "location" from "inventory_single" where ("location" = 'LOC-01') and ("sku" = 'SKU-01') for update
2019-04-18 08:08:13.930 PDT [11853] toyinventory@toyinventory LOG: execute S_4: select "id", "sku", "qty", "location" from "inventory_single" where ("location" = 'LOC-02') and ("sku" = 'SKU-01') for update
2019-04-18 08:08:13.933 PDT [11853] toyinventory@toyinventory LOG: execute S_6: select "id", "sku", "qty", "location" from "inventory_single" where ("location" = 'LOC-01') and ("sku" = 'SKU-01')
2019-04-18 08:08:13.956 PDT [11853] toyinventory@toyinventory LOG: execute S_5: select "id", "sku", "qty", "location" from "inventory_single" where ("location" = 'LOC-02') and ("sku" = 'SKU-01')
2019-04-18 08:08:13.959 PDT [11853] toyinventory@toyinventory LOG: execute S_8: update "inventory_single" set "qty" = $1 where ("inventory_single"."location" = 'LOC-01') and ("inventory_single"."sku" = 'SKU-01')
2019-04-18 08:08:13.959 PDT [11853] toyinventory@toyinventory DETAIL: parameters: $1 = '2'
2019-04-18 08:08:13.963 PDT [11853] toyinventory@toyinventory LOG: execute S_7: update "inventory_single" set "qty" = $1 where ("inventory_single"."location" = 'LOC-02') and ("inventory_single"."sku" = 'SKU-01')
2019-04-18 08:08:13.963 PDT [11853] toyinventory@toyinventory DETAIL: parameters: $1 = '0'
2019-04-18 08:08:13.964 PDT [11853] toyinventory@toyinventory LOG: execute S_1: COMMITThis is pretty significant progress if you compare these results to our initial implementation. At the cost of row level locking, we can leverage our database to provide a pretty consistent experience for the caller.
Summary
In this and the previous post we have worked our way from a very basic solution to one that makes some trade-offs with locking but is able to provide some useful consistency. There are a number of ways to approach this problem, and we have made an effort to explore several (including some less successful attempts like utilizing a more aggressive isolation level).
Hopefully, you found this useful if you were looking for examples designing systems with relational databases or applications of Scala and Slick.